Titanik verisine bir bakış
merhaba!
bugün sizlerle seaborn kütüphanesi altında hazır olarak bizlere sunulan Titanic gemisinin son yolculuğunda bulunan yolculara ait verileri keşifsel olarak inceleyecek ve üstünde yorumlar yapacağız. yazı boyunca veri dönüşümü, veri görselleştirme ve elde ettiğimiz çıktıların yorumlamasını yapacağız. analize ve kodlamaya başlamadan önce veri setimize nasıl erişebileceğinizi kısaca ifade edeyim. veriye, seaborn kütüphanesinin içinden direkt olarak erişebiliyoruz.
import seaborn as snsimport pandas as pdimport matplotlib.pyplot as plt
data = sns.load_dataset("titanic")
ancak gördüğüm kadarıyla seaborn bize bir metadata, yani verinin verisini vermiyor. metadata, özellikle üstünde çalıştığımız verinin ne olduğunu, sütunların hangi veriyi ne şeklde sağladığının bilgisi işimizi oldukça kolaylaştıracaktır. bu veri seti içinde “pclass” isimli bir sütun bulunmakta. sütunun içindeki veriler sadece 1 2 ve 3 olacak şekilde ifade edilmiş. bu sayılar aslında yolcuların bilet sınıflarını, yani first class, second class veya third class yolcu olduklarını ifade etmektedir. eğer metadata’da bununla ilgili bir açıklama bulunmasaydı bu durumu kendimiz keşfetmemiz gerekecekti.
önce verimizin sahip olduğu sütunları görelim.

burada diğer verilerden üretilmiş sütunlar da bulunmaktadır. örneğin, “pclass” ve “class” aslında aynı şeyi ifade etmektedirler. sadece, pclass sütununda bu değerler 1,2 ve 3 iken, class sütununda bu değerler “First”, “Second” ve “Third” olarak ifade edilmiştir. Kaggle üzerinden ulaştığım veriye ait metadataya bir göz atalım. bu metadata, kaggle üzerinde düzenlenen yarışmaya ait olduğu için metadata’da geçen bazı veriler veri setimizde yok.

bu veri setiyle birlikte, hayatta kalma durumu; kazadan sağ kurtulanlar için 1, kazada hayatını kaybedenler için 0 olacak şekilde, kişinin sınıfı (uçaklardaki first class, economy gibi class’lar); 1–2–3 olacak şekilde, yanında kardeşinin veya eşinin olup olmaması; sibsp sütununda 1–0 olacak şekilde, yanında ebeveyn ya da çocuğu olup olmaması; parch sütununda 1–0 olacak şekilde, bilete ödemiş olduğu ücret; fare sütununda integer şeklinde, gemiye bindiği yer; embarked sütununda C, Q ve S olarak ifade edilmiştir. söz konusu metadata eski olduğu için güncel verimizde bu sütunları daha iyi ifade edecek başka sütunlar da mevcut.
hazırsak, başlayalım!
öncelikle, data.head() diyerek veri setimizi baştan görelim.

15 adet sütunumuz mevcut. bazı sütunlar tekrarlı. örneğin, “survived” ile “alive”, “pclass” ile “class” ve “embarked” ile “embark_town” aynı verinin farklı şekillerde ifade edilişi. biz de kendimiz, veriden bu şekilde bir yeni sütunlar oluşturabiliriz. mesela, survived 1–0 veya alive yes-no benim hoşuma gitmedi. biz, survived 1 olanlar için “kurtuldu”, olmayanlar için “kurtulamadı” gibi bir sütun oluşturabiliriz. siz isterseniz bunları farklı bir şekilde ifade edebilirsiniz. ben kurtuldu-kurtulamadı olarak kurguluyorum.
data["survive_or_not"] = data["survived"].replace( {1: "kurtuldu", 0: "kurtulamadı"})
sütunumuzu hazırladıktan sonra, “who” sütununa göre bir görselleştirme gerçekleştireceğiz. ancak önce neden “who”yu seçtik?

çünkü who stünu, sex’in aksine bir de “child” kategorisi içermekte. böylece kadınlar, erkekler ve çocuklar arasında hayatta kalma oranını görebileceğiz.
sns.countplot(x="who", hue="survive_or_not", data=data)bu bize bir görsel verecek. şöyle bir şey görebiliyor olmanız gerek,

bu görsele baktığımız ilk dikkat çeken, erkeklerin çoğunluğunun kurtulamamış olmasıdır. kadınların çoğunluğu hayatta kalmıştır. çocukların yarısından fazlası hayatta kalmıştır. peki ya yüzdelik olarak görmek istersek?
data[data["who"] == "woman"]["survive_or_not"].value_counts(normalize=True)peki neden “normalize=True” kullandık? normalde value_counts bize sayısal olarak dağılımları verecekti. ancak biz sayısal dağılımları değil, yüzdesel dağılımları istiyoruz. onun da bize dönüşü şu şekilde oluyor.

kadınların %75,64'ü hayatta kalmış. aynı kodu erkekler için çalıştırdığımızda bize %16,38 ve çocuklar için çalıştırdığımızda %59,03 oranını veriyor.
toplu bir halde görmek için şu kodu kullanabiliriz.
data.groupby("who")["survive_or_not"].value_counts(normalize=True)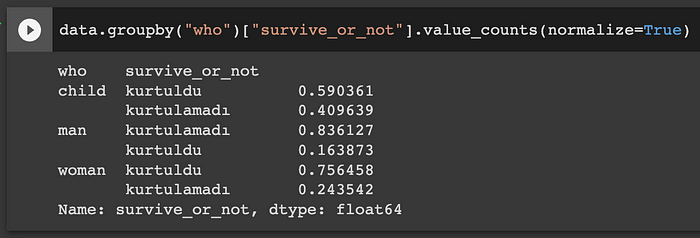
burada kalmayalım ve devam edelim. mesela, bilet sınıfları var demiştik. first, second ve third olmak üzere pahalıdan ucuza sınıflar mevcut. bu sınıflar arasında hayatta kalma, kurtulma dağılımı nasıl? önce grafik olarak göz atalım. daha sonra yüzdesel olarak bakabiliriz veya.. grafiğimizde yüzde etiketleri ekleyebiliriz. hadi yapalım! burada bir takım kod yazmamız gerekecek, ancak bu kodu her yerde kullanabilirsiniz. bu sebepten ötürü aşırı faydalı olacağını düşünüyorum. önce normal bir şekilde grafiğimizi oluşturalım.
sns.countplot(x="class", hue="survive_or_not", data=data)bunun üzerinde bir işlem yapabilmemiz için bir değişkene atayalım.
ax = sns.countplot(x="class", hue="survive_or_not", data=data)artık grafiğin diğer değişkenlerine ax. üzerinden ulaşabileceğiz. ilk seferde yazarken adım adım ilerleyeceğim ki aslında kodun göründüğü kadar karmaşık olmadığını ifade edebilelim.
ilk işimiz bir for döngüsü yaratmak olacak. her for döngüsünde bir barı ele alacak ve ona göre işlemler yapacağız. yazacağımız her kod bu for döngüsünün içinde olacak.
for p in ax.patches:o zaman başlayalım! ilk ayar kodumuz.
for p in ax.patches: height = p.get_height() # oluşturulan her bar'ın yüksekliğini al.
kodumuz, oluşturulan her bar’ın yüksekliğini alıyor ve bunu height değişkenine ekliyor.
for p in ax.patches: height = p.get_height() # oluşturulan her bar'ın yüksekliğini al.# her bar'a bir text ekle. ax.text(x = p.get_x()+(p.get_width()/2), # text'in x koordinatöründeki konumu, barın tam ortasında olması için iki yana yaslı
burada dikkat etmemiz gereken, bundan sonra yazılan her şey ax.text() parantezleri içinde yazılıyor. ilk kodumuz barın x konumu için ve genişliğini alarak text’imizin tam olarak bar’ın ortasında olmasını sağlayacağız.
ax = sns.countplot(x="class", hue="survive_or_not", data=data)for p in ax.patches: height = p.get_height() # oluşturulan her bar'ın yüksekliğini al.# her bar'a bir text ekle. ax.text(x = p.get_x()+(p.get_width()/2), # text'in x koordinatöründeki konumu, barın tam ortasında olması için iki yana yaslı y = height+3, # text'in y koordinatındaki yeri, bar'ın hafif üstünde olması için + 3
y, text’imizin dikey konumunu bize ifade ediyor. eğer olduğu gibi bırakırsak, direkt olarak bar’ın üstüne koyacaktır. bu okunurluğu düşüreceği için, y = height + 3 diyoruz. + olması barın uç noktasının üstüne yerleşeceği anlamına geliyor. eğer bar’ın içine yani üst noktasının altına yazmak istersek eksi koymamız gerekecek.
ax = sns.countplot(x="class", hue="survive_or_not", data=data)for p in ax.patches: height = p.get_height() # oluşturulan her bar'ın yüksekliğini al.# her bar'a bir text ekle. ax.text(x = p.get_x()+(p.get_width()/2), # text'in x koordinatöründeki konumu, barın tam ortasında olması için iki yana yaslı y = height+3, # text'in y koordinatındaki yeri, bar'ın hafif üstünde olması için + 3 s = '{0}'.format(height), # veri label'ı, verimiz float olsaydı {:.2f} olarak güncelleyecektik.
s, bizim asıl etiketimizi ifade etmekte. burada format kullanma sebebimiz aslında bu kodun hazır bir kod olmasını sağlamak. açıklamada da yazdığımız gibi, eğer küsüratlı bir değer olursa buradaki {0} değerini {:.2f} olarak güncelleyecektik.
ax = sns.countplot(x="class", hue="survive_or_not", data=data)for p in ax.patches: height = p.get_height() # oluşturulan her bar'ın yüksekliğini al.# her bar'a bir text ekle. ax.text(x = p.get_x()+(p.get_width()/2), # text'in x koordinatöründeki konumu, barın tam ortasında olması için iki yana yaslı y = height+3, # text'in y koordinatındaki yeri, bar'ın hafif üstünde olması için + 3 s = '{0}'.format(height), # veri label'ı, verimiz float olsaydı {:.2f} olarak güncelleyecektik. ha = 'center') # yatay konumlandırmayı merkez (center) yapıyoruz.
son olarak horizontal allignment, yani yatay konumlandırmayı merkez yapıyoruz. kodumuzu yazdığımıza göre çalıştırabiliriz!

artık sütunlarımızın üstünde o sütunlara ait değerler de bulunuyor. bu en basit yoldu, daha karmaşık ve görsel olarak daha güzel gözükecek yollar da olabilir.

bu noktadan sonra çok daha rahat ilerleyebileceğiz. çünkü seaborn bize ayrı ayrı ayar yapmadan sadece datayı vererek sonuç alabilme imkanı vermekte. fare sütununun, bilete ödenen fiyat olduğunu söylemiştik. bunu bir de görsel olarak görelim.
ax = sns.barplot(x="class", y="fare", data=data, ci = 0)for p in ax.patches:
height = p.get_height()
ax.text(x = p.get_x()+(p.get_width()/2),
y = height+0.5,
s = '{:.2f}'.format(height),
ha = 'center')
ci değeri, güven aralığını çizmekte. eğer bu değeri manipüle etmezsek bize şöyle bir grafik verecek.

ancak biz grafiklerimize label eklediğimiz için bu çubuğu istemiyoruz, bu sebepten ötürü ci = 0 diyoruz.

evet, sınıflar arasında ortalama bilet fiyatlarını gördük. peki, 3 farklı liman olduğunu biliyoruz. limanlardan binenlerin sınıf dağılımı nedir?
ax = sns.countplot(x="embark_town", hue="class", data=data)for p in ax.patches:
height = p.get_height()
ax.text(x = p.get_x()+(p.get_width()/2),
y = height+2,
s = '{:.2f}'.format(height),
ha = 'center')

bu görsel bize, genel olarak binen yolcuların çoğunluğunun southampton’dan bindiğini, en az binişin queenstown’dan olduğunu, limandan binen yolculara oranla en yüksek first class yolcu oranının cherbourg’a ait olduğunu görebiliyoruz. bir grafik oluşturduktan sonra onun üstünde yorum yapabilmek, grafiği oluşturmak kadar önemli. bu grafiğe göre yolcuların çoğunluğu southampton’dan binmiş görünmekte, ancak toplam binen yolcu bazında en çok first class yolcusu cherbourg’dan binmiş görünmekte. bu da aslında bu keşifsel analizi yapmamızın temel sebebi. burada durmayalım ve devam edelim. limanlara göre kurtulma durumu nedir?
ax = sns.countplot(x="embark_town", hue="survive_or_not", data=data)for p in ax.patches:
height = p.get_height()
ax.text(x = p.get_x()+(p.get_width()/2),
y = height+0.2,
s = '{:.2f}'.format(height),
ha = 'center')
burada bizi ilginç bir tablo karşılıyor.

southampton’dan binen her 3 kişiden biri kurtulamazken, cherbourg’tan (az önce first class yolcuların ağırlıklı olarak bindiğini gördüğümüz liman) yolcuların yarısından fazlası kurtulmuş olarak görülüyor. daha önce yaptığımız görselleştirmelerde, first class yolcularının çoğunluğunun hayatta kaldığını bildiğimize göre, bu tablo aslında o kadar da ilginç değil. devam! adult_male ile ilgili analiz yapmadan önce son olarak, bir de sınıflar bazında yaş ortalamasına bakalım.
ax = sns.barplot(x="class", y="age", data=data, ci = 0)for p in ax.patches:
height = p.get_height()
ax.text(x = p.get_x()+(p.get_width()/2),
y = height+2,
s = '{:.2f}'.format(height),
ha = 'center')

sınıf yükseldikçe yaş ortalaması da yükseliyor. şimdi adult_male üzerinde bir inceleme yapalım. bu ne anlama geliyor, 18 yaşından büyük erkekler adult_male üzerinde True olacak şekilde gösterilmiş. erkeklerin (özellikle düşük class erkeklerin) çoğunlukla hayatını kaybettiklerini biliyoruz. peki bu grafiğe nasıl yansımış? bunun için önce bir adet dataframe oluşturacağız. çünkü bu şekilde şu an şöyle görselleştirme ile karşılaşıyoruz:

ancak biz sdaece “true” değerlerin grafiğini görmek istiyoruz. bunun için şöyle bir kısıtlama yapacağız.
data_adult_male = data.loc[data.adult_male == True]bu çok basit bir limitleme, bundan sonra daha önce yazdığımız kodlarda ufacık bir değişiklik yapacağız.
ax = sns.countplot(x="adult_male", hue="survive_or_not", data=data_adult_male)for p in ax.patches:
height = p.get_height()
ax.text(x = p.get_x()+(p.get_width()/2),
y = height+4,
s = '{:.2f}'.format(height),
ha = 'center')
bu arada kodlar arasında y = height+ değeri sürekli değişiyor. bunu, grafiğin üstüne gelen label’ı bar’ın ucuna ne çok uzak ne çok yakın olacak şekilde konumlandırmaya çalışıyorum.

toplamda 537 adet yetişkin erkeğin sadce 88'i kurtulabilmiş. peki, bu yetişkin erkeklerin sınıflara göre hayatta kalma sayıları nelerdir?
ax = sns.countplot(x="class", hue="survive_or_not", data=data_adult_male)for p in ax.patches:
height = p.get_height()
ax.text(x = p.get_x()+(p.get_width()/2),
y = height+2,
s = '{:.2f}'.format(height),
ha = 'center')

sınıflar arasıdaki hayatta kalma farkını, konu yetişkin erkekler olunca daha net bir şekilde görebilmekteyiz.
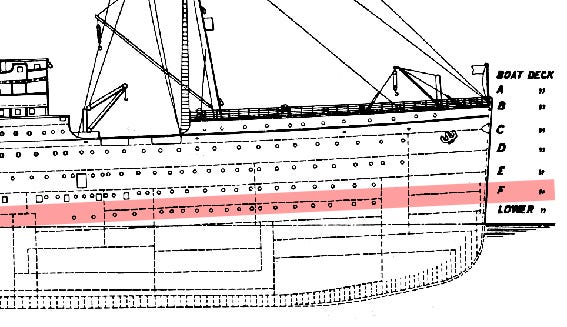
son olarak, deck, yani kişilerin kaldıkları odaların gemideki konumlarına göre hayatta kalma oranlarına bakalım. Önce deck ne, gördüğümüze ne diyeceğiz ona bir bakalım.
burada dikkat etmemiz gereken bir şey var. öncelikle verimizde boş veri, yani NaN veya null var mı ona bir göz atalım.
data.isnull().sum()
görüyoruz ki deck verimizde 688 adet boş veri var. bu sebepten ötürü sadece dolu olanlar üzerinden yorum yapmaya çalışalım. öncelikle nan olan verileri “bilinmiyor” olarak düzenleyelim.
cat = ['C', 'E', 'G', 'D', 'A', 'B', 'F']
new_deck = []for deck in data["deck"]:
if deck in cat:
new_deck.append(deck)
else:
new_deck.append("bilinmiyor")data["deck"] = new_deck
data_deck = data.loc[data["deck"] != "bilinmiyor"]
A’dan F’ye kategoriler içerisinde olanları direkt olarak listemize atarken, olmayanlar için bilinmiyor yazıyoruz. sonrasında yeni bir data_deck değişkeninin içine atıyoruz.
ax = sns.countplot(x="class", hue="survive_or_not", data=data_deck, order=['A', 'B', 'C', 'D', 'E', 'F'])for p in ax.patches:
height = p.get_height()
ax.text(x = p.get_x()+(p.get_width()/2),
y = height+2,
s = '{:.2f}'.format(height),
ha = 'center')
order vermemizin sebebi, rastgele olarak bize grafik vermesi. biz a’dan f’ye sıralı istiyoruz.

decklere göre hayatta kalma sayılarına göre görselleştirebildik. son olarak, age sütunumuzda biraz boş değer olduğunu görüyoruz. age kategorisi float bir kategori olduğu için bu kategorideki boş değerleri, tüm sütunun ortalaması ile doldurabiliriz.
data[“age”] = data[“age”].fillna(data[“age”].mean())böylece data’mızda neredeyse hiç boş veri olmadığını görebiliriz.

evet! artık yazımızın sonuna geldik. burada temel amaç, titanic veri seti özelinde yapabileceğimiz görselleştirme araçları, plot’umuza label eklemek, boş kategorik ve sayısal verileri nasıl düzenleyebileceğimizi görmekti.
başka bir yazıda görüşmek üzere, titanic hakkında detaylı bilgi almak isterseniz Evrim Ağacı’nın şu videosunu kesinlikle izlemenizi tavsiye ederim. bir sonraki yazıya dek, hoşçakalın!
